

In this post we’ll look at the problem of mid-deployment remote target dependencies and some ways to handle them.
The Problem:
It is a familiar problem to deployers. For my release into Production, I need to run steps X, Y and Z, in that order. The only trouble is, step Y is on a different set of target servers to step X and Z. In other words, I need to run step X, then wait while step Y completes on a different set of servers, before finally completing with step Z back on the original set of servers.
Further complication is added because this release model may need to be run in development, test, production and possibly other environments. I need to make sure that when step Y is run, it is on the matching targets for that environment.
In this post we’ll look at some possible solutions to this problem and their benefits and drawbacks.
The Possible Solutions:
A Pipeline
So, I hear you say, “Use a Pipeline!”. Create three steps in the pipeline and run them sequentially, and then duplicate these three steps for all the target environments, but with the correct parameters for those environments.
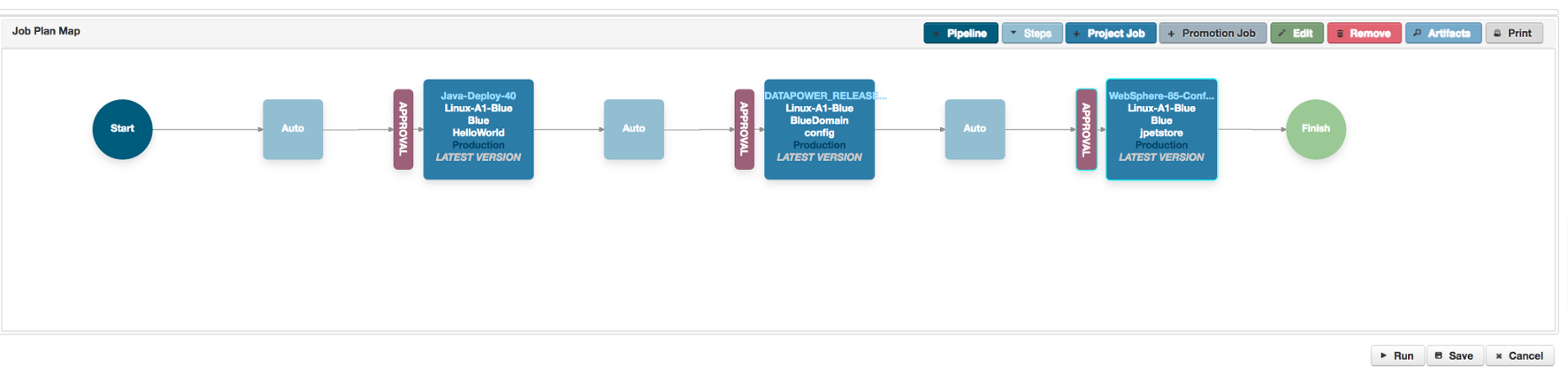
And I would agree, this could work in most situations. But it isn’t always ideal. A pipeline step should be an atomic piece of work, independent of other pipeline steps. For example, what if the first step on a server, the step X above, generates some state that needs to be passed to the final step Z? What if step X opens some resource that shouldn’t be closed until the end of the execution on that server?
In this case you’ll need to find a way of stopping execution on the first set of servers, whilst the tasks in step Y are completed on the second set.
The direct call
One way to do this would be for Server A to make a direct, synchronous call to Server B, and on completion of the
Server B tasks, continue execution on Server A. This will work where there is only one Server A and one Server B. But what if we are deploying to a cluster? Now we have lots of Server A’s in Cluster A and lots of Server B’s in Cluster B . In this case its not clear how we’d manage communications between the two.
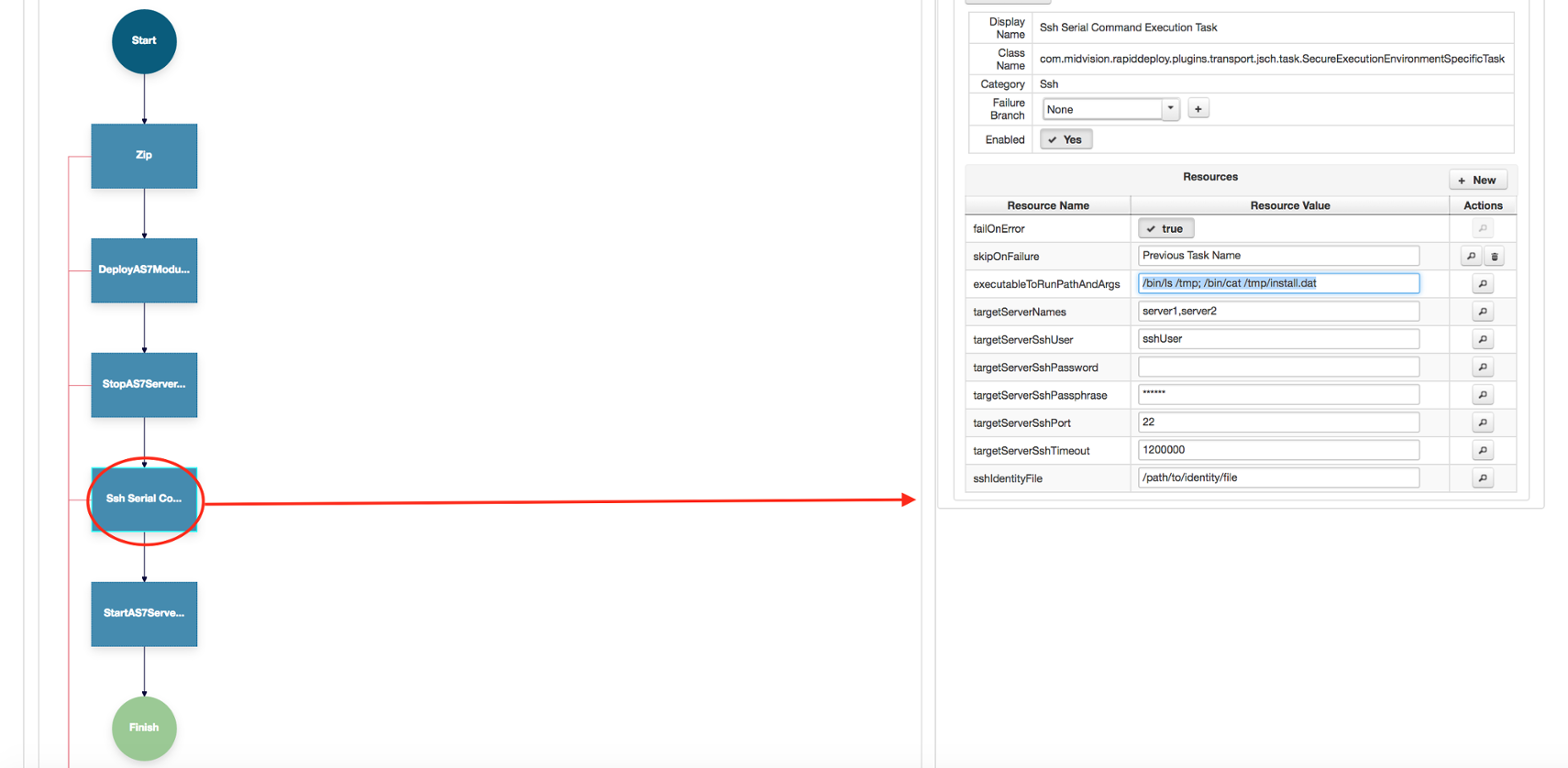
Would each Server in
Cluster A be paired with one from Cluster B? Its also not a given that a server in Cluster A would have a clear li
ne of sight to the server in Cluster B, and we’d also need to manage the credentials between them effectively without compromising security. What if they are in different security zones? Perhaps Server B is in the Red zone whilst Server A is in the white zone. Direct communications from white to red would not be desirable and would probably fall foul of IT Security rules. So whilst the direct call is possible, it really isn’t desirable in many situations.
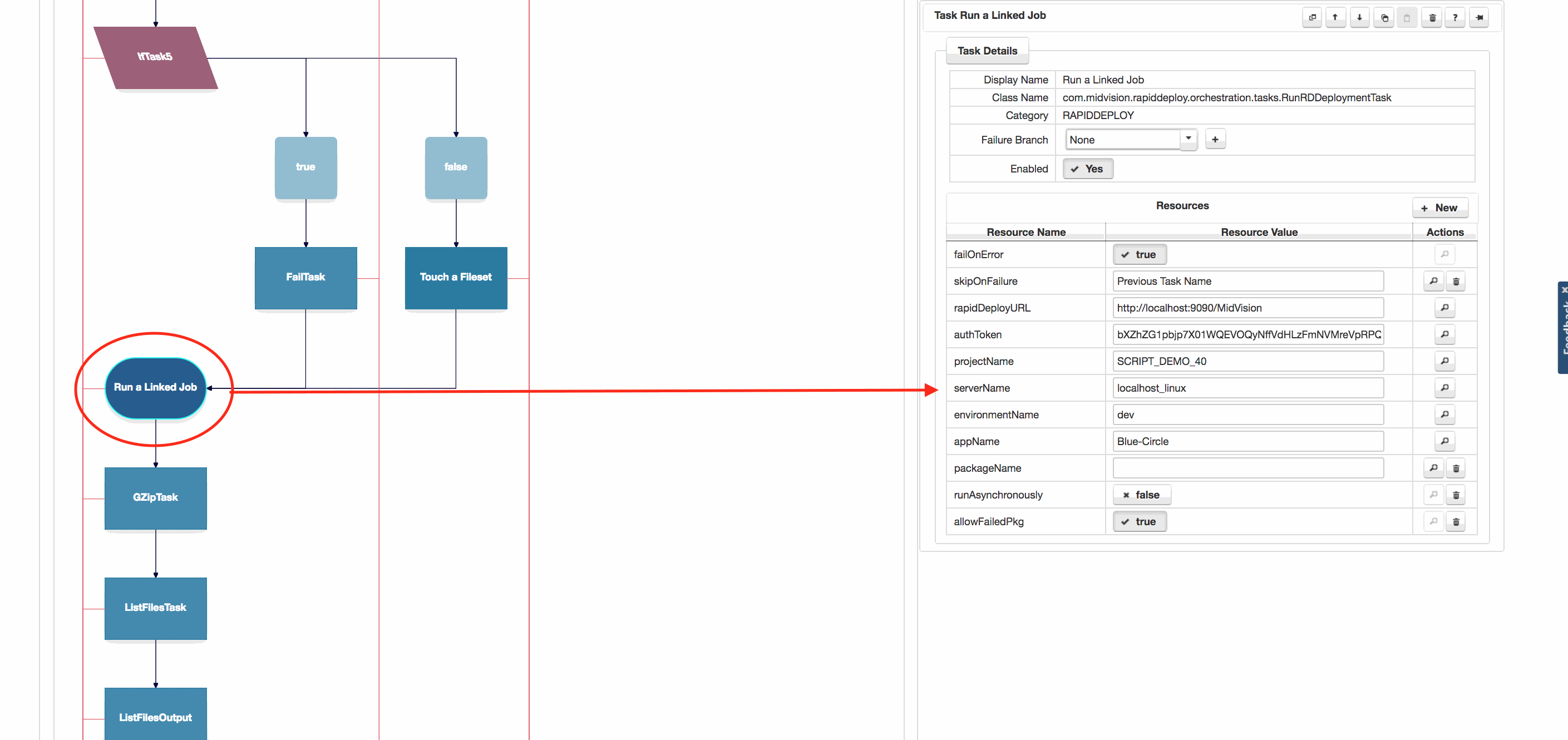
Phone Home
Another mechanism would be for the job running the deployments on Cluster A, lets call this Job A, to ‘Call home’ to the framework server where the jobs were initiated, and call another job, lets call this Job B, that runs the tasks on Cluster B. It would be be up to Job B to worry about managing the deployment to the cluster. All Job A would need to do is make the synchronous call to the framework with the correct credentials for Job B and the correct information about the target environment matching this one (e.g. Development, Test or Production). If the model is environment neutral, the target information would need to be parameterised so it could be different for each target environment.
Conclusion
There are several ways to achieve the aim stated at the start of this post. Hopefully I’ve shown that there isn’t one outright winner and mechanism you choose will be dependent on what you’re trying to achieve, and the topology of the target environment(s). What should be clear however, is when you’re looking for a deployment automation solution, you’ll need a flexible tool that is designed to handle any of these scenarios out of the box.