Failure and Rollback
How to handle failure, perform cleanups and rollback in RapidDeploy
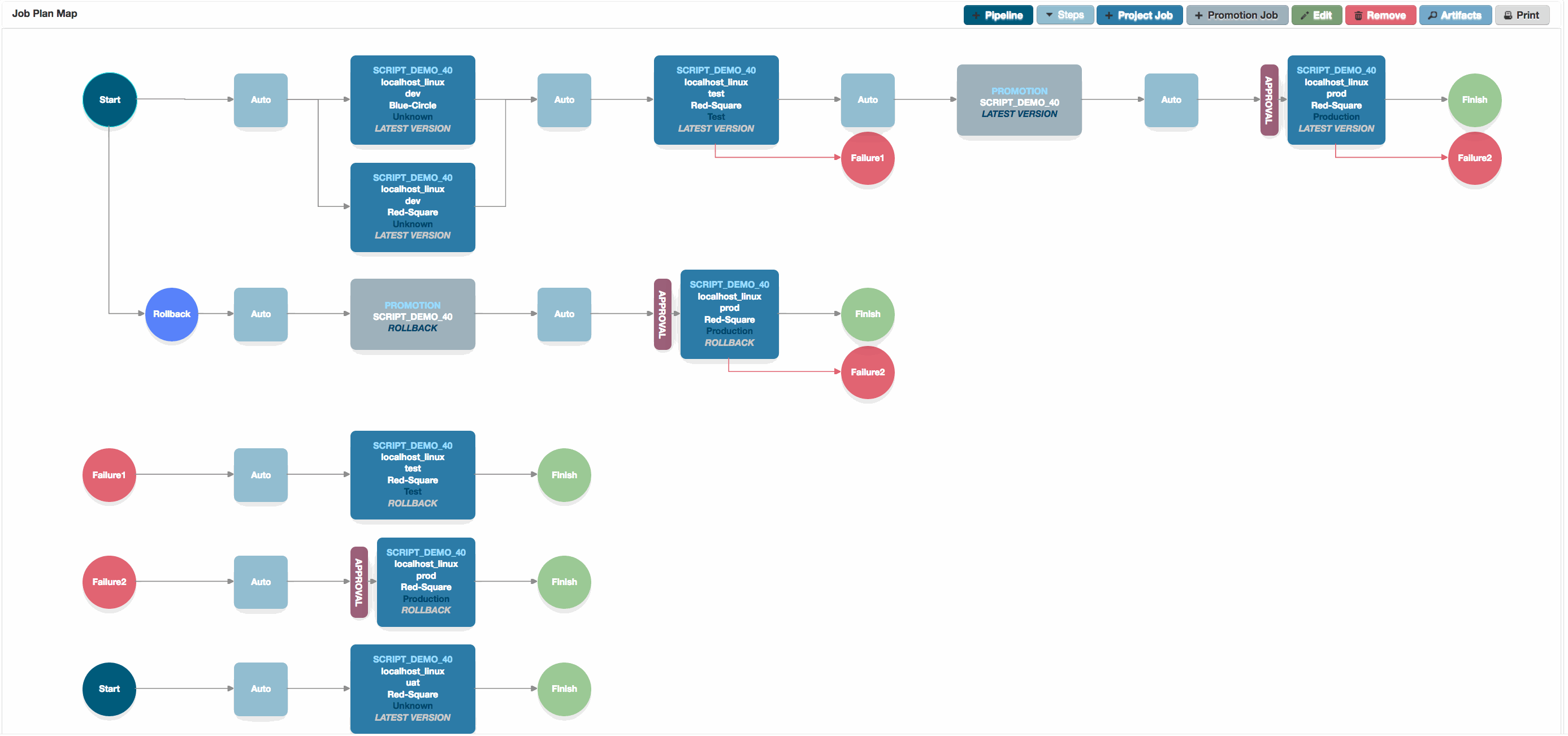
Job Plan Canvas
The Job Plan canvas, showing standard pipelines, as well as configured failure and rollback pipelines.
1. Atomic (transactional) deployment steps
Some of the deployment tasks in RapidDeploy have rollback-on-failure built in, and therefore perform transactional change. These tasks typically make use of transactional abilities in the target technologies, such as for Database changes.
For these tasks, if the deployment fails during the task execution, the configuration acted upon by the target is returned to the pre-deployment state. It should be noted that only the specific task actions are rolled back. If there are multiple tasks in a job that run for a specific execution, all the tasks up to the point of the failed transactional job will still have completed and might still need to be ‘undone’.
So for example a job that moves some files from one location to another, and then performs a database schema update, might rollback the database changes on failure of that task, but leave the moved files in their new location. If these files need to be moved back, we need to enlist the suport of ‘Server Orchestration Failure Branches’.
Click to enlarge
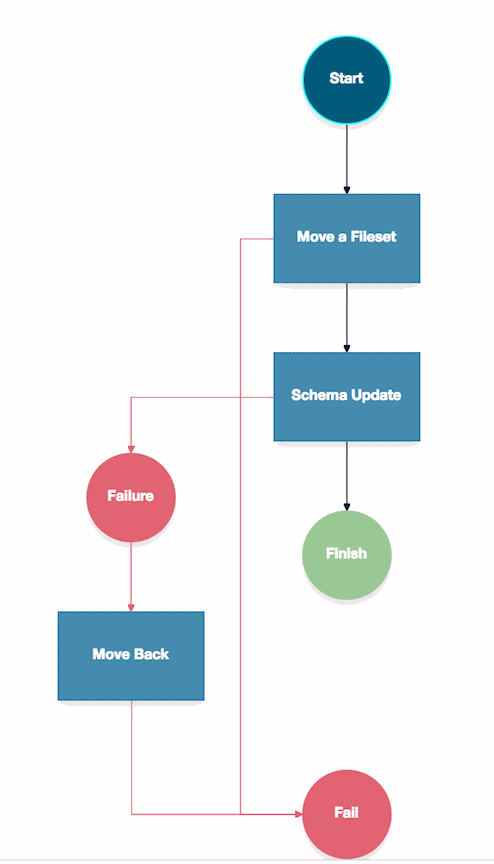
2. Server Orchestration failure branches
On the Project Orchestration tab, the Orchestration map will start with one failure branch. This is the defaut setting. All tasks with ‘failOnError‘ set to true will, by default, subscribe to this failure branch, which simply fails the job.
Any task can add a new failure branch, or subscribe to any other failure branch. The example shown has two failure branches the default fail, and failure.
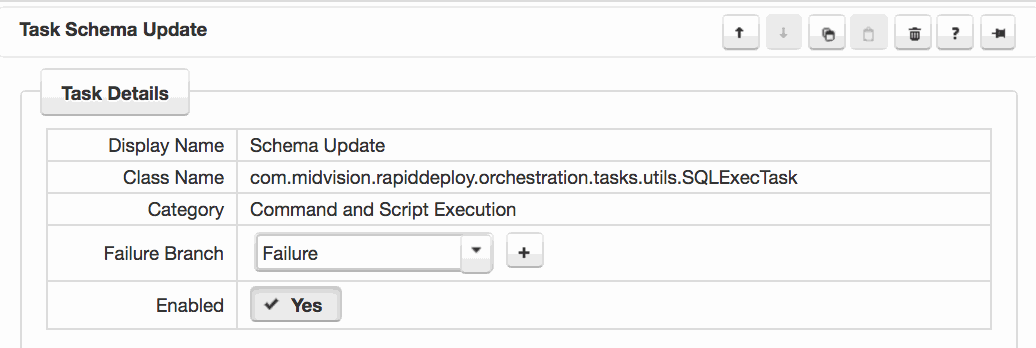
You can choose an existing failure branch, or add a new one by selecting the task and choosing from the drop-down in the ‘Failure branch‘ field or clicking the ‘+‘ button. You can add any tasks to the failure branch in order to accomplish the required cleanup.
Continuing with the example. If the schema update fails, here we add a failure branch with another move task to move the files back to their original location.
Click to enlarge
3. Job Plan Failure Pipelines
A Job Plan can consist of one or more standard deployment pipelines. Here we’ll see how we can also configure failure and rollback pipelines in the Job Plan.
If a pipeline fails during a deployment of a project target, we’ve so far seen how to take corrective measures on the target server(s) themselves. However, we might under some circumstances, want to run another job on the target to revert all the changes back to a previous version, or run some specific rollback orchestration.
To achieve this, we add failure pipelines on the Job Plan Edit canvas.
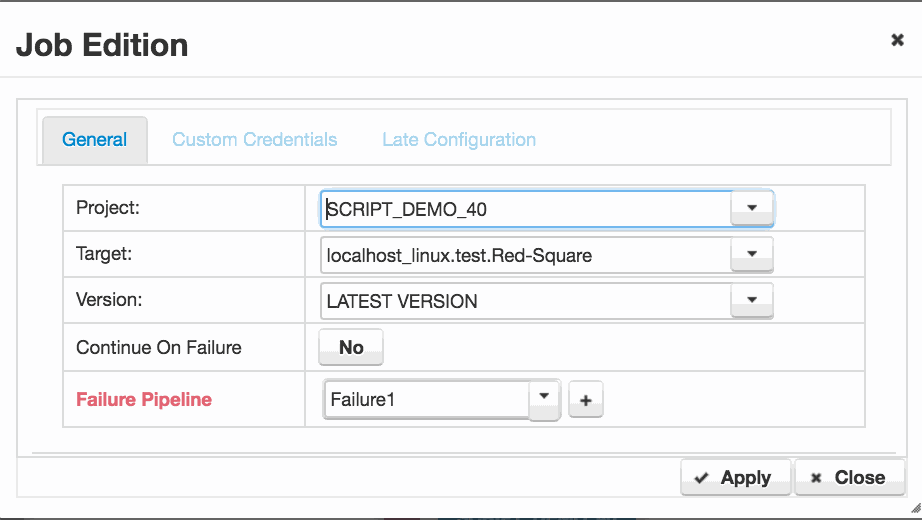
On the Job Plan Edit canvas, we can add a failure pipeline, or subscribe to an existing failure pipeline for any ‘Project Job‘.
We edit the ‘Project Job‘ and add or select a failure pipeline in the ‘Failure Pipeline‘ field.
The failure pipeline can run any project target combination in just the same way as a deployment pipeline. Typically you will run the same ‘Project Job‘ but selecting a specific version to roll back to. The special ‘ROLLBACK‘ version may also be selected, which returns the target to the previous successfully deployed version for this target.
You can see failure pipelines configured in this way in the main picture at the top of this page.
Click to enlarge
4. Rollback Pipeline
So far we have only considered failure scenarios. However there is also the possibility that all our deployment tasks succeed, only for us to discover that some piece of critical functionality in the deployed application is faulty. In this case we’ll need to either fix forward, or perform a rollback.
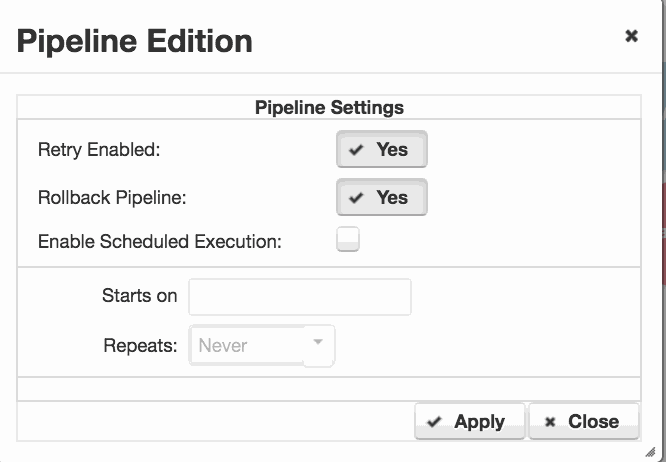
In order to perform a rollback, we configure a rollback pipeline. On the ‘Start‘ point of the pipeline, we double click to open the ‘Pipeline Edition‘ dialog.
Set ‘Rollback Pipeline‘ to ‘Yes‘ and Apply the change. A rollback pipeline is automatically configured with all of the original pipeline steps, but having all versions set to ‘ROLLBACK‘ You can edit this pipeline as required to create your preferred rollback scenario.
In the example at the top of the page, we’ve removed most of the default job steps and just configured our rollback to promote and then deploy the ‘ROLLBACK‘ version to our production environment.
Click to enlarge