
Abstract:
Software configuration management and build/CI tools and processes are relatively simple to implement and are therefore mature in many, if not most organisations. Moving to continuous delivery can prove somewhat more complex, and organisations can sometimes struggle to adopt a coherent, integrated and extensible process that applies across their estate.
The state of play:
Software Configuration Management repository tools such as Subversion and Git have been the industry standard mechanism for managing source code for many years. Most organisations would not try to do development work without them. Many organisations also have relatively mature Continuous Integration (CI) processes and these have been quite easy to adopt in an organic way on top of the SCM tools, by leveraging products such as Jenkins or Bamboo. Adoption of these tools will tend to lead naturally to a requirement to manage your built artefacts and the dependencies between them. This might be achieved using Maven, Nexus or another tool.
So far, so good. Implementation of these tools and processes follows a relatively linear path, and the approaches used are all fairly similar between products. It could be said that these have followed the ‘low hanging fruit’ metaphor because the requirements and tasks they seek to achieve are relatively simple: Store and version my code, build it and manage its dependencies. They are also relatively easy to adopt: we just need a few build servers and repositories we can manage independently of the rest of our organisation. We don’t need a complete shift in the way we work. Adoption can be by small parts of the enterprise and done independently if necessary on a project by project basis.
The next step and why it’s hard:
OK, so the next logical requirement is now to deploy the built artefacts, and their dependencies, to the various target environments for testing and ultimately production use. Now here is where things can get somewhat more complicated. Once we can reliably deploy to each of these target environments, we might like to link these deployments together into a continuous deliver pipeline.
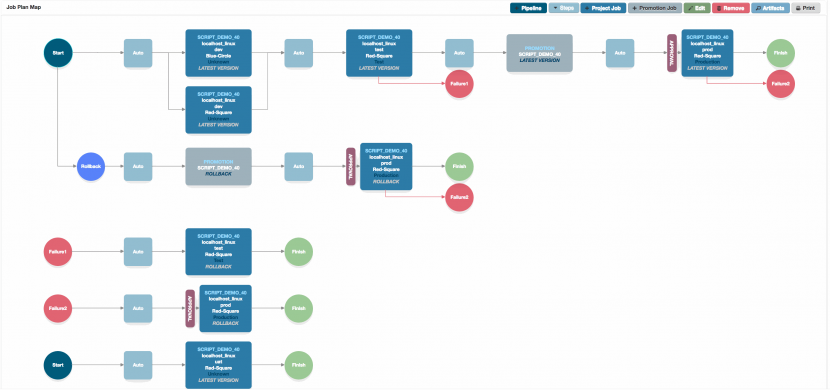
So why is this more complicated than CI? Here are some of the reasons.
- We build in one environment, we deploy to many. So whilst its true that we want to keep each target environment as similar to all the others as possible, still each target environment will likely and inevitably be different in some subtle (or not so subtle) ways to all the others. We will need to manage those differences, so that incorrect configurations don’t cause us issues that we only discover in production.
- Configuration differences. Each target environment will have configuration differences to the other environments. For example database URLs, passwords, load scaling factors and many many more.
- Deployment differences. We may need to run some deployment steps in some environments that we don’t run in others. We should try not to do this, but sometimes it is necessary.
- We will deploy to environments that may have different starting versions. For example, if lots of our deployments fail to pass UAT, then UAT will likely be on a much later version to production, as it’s had more deployments of newer code to fix the failures. Deploying to UAT and production in the same invocation of a pipeline means the deployable artefact needs to take account of this. We must bring both UAT and Production up to the same desired state, but from different starting points.
- We need to handle the possibility that we’ll need to back out production code out. We need to handle the scenario where the deployment itself fails, leaving the environment in an inconsistent state. Further, the successful deployment may be found to be faulty in some critical way, either in immediate post deployment testing, or even worse, during normal operation some time later. If we cannot fix forward, we need to back out, and we need an effective, repeatable and reliable way of doing this. We don’t want to have to figure out how to do it at 2am on a Sunday morning with a skeleton staff!
- Many different components may need to be deployed as part of a ‘composite’ release. Each of these components will have its own deployment requirements, steps, configurations and back out requirements. In the event of one needing to be backed out, one or more other dependent components may also need to be backed out. There may be deployment dependencies in the order these components can be deployed, and checkpoints and manual steps may need to be performed between components. Other components may be deployable in parallel.
- A large release may require close collaboration between many different teams and expertise. This can often be difficult to coordinate and miscommunication may lead to errors.
- Deployments to sensitive environments require enterprise level security, both at the physical and management levels. Questions such as ‘who can deploy to production’ and ‘what approvals and quality gates are in place?’ need to be answerable, as well as ‘Who has physical access to the production servers’ and ‘what controls exist to prevent unauthorised change?’
- If an environment stops working, we need to know what changed that stopped it from working, who performed that change and why was it done. Comparing environments can be notoriously difficult and might be dependent on the technologies deployed and the interfaces they provide.
Possible solutions – No ‘Magic Bullet’
Vendors have approached the problems described above and have addressed them using different techniques. So far, a ‘magic bullet’ has not been found and there is not yet an agreed best practice on how to manage the remainder of the software delivery process. Of course the high level process are agreed upon – Continuous Delivery Pipelines, Orchestration, high levels of Automation – but the implementation is less mature and the implementation methods vary significantly.
The first, and simplest solution is to extend your existing CI tools to perform Continuous Delivery. The extensible nature of tools like Jenkins provide a framework for engineers to develop plugins to achieve this – or at least to automate the delivery pipeline beyond the creation of software assets. It is also the case that many enterprises that have chosen this route have met with some success in creating comprehensive automated software delivery pipelines that meet their requirements.
The second possible solution is to take an existing workflow automation tool and extend it to cover all of the required deployment specifics of an organisation. Again, many enterprises have taken this route with some success.
However, it is our belief that for many organisations these approaches do not scale or provide the functional requirements that many mid to large organisations require. The most notable aspect where these tools fall short are around Release Automation and Release Orchestration. Partly, this is a function of the fact that these tools were built ‘from the ground up’ to perform different jobs. We believe that Continuous Delivery is a complex multi-faceted discipline that requires tools built to specifically address the requirements and challenges it presents.
In the remainder of this article, we tackle some of the issues mentioned above and highlight some of the ways a dedicated Release Automation and Release Orchestration tool such as RapidDeploy can address these.
What might a ‘magic bullet’ look like?
Actually, I think this is a harder question to answer than it might at first appear. Ok, so I know a lot of people will say some or all of the following:
- Accessible Web based solution that satisfies all of the requirements of such a tool in one application.
- Audit trails – who deployed to which environment and when. What approvals were granted, which quality gates were passed. Easy to access detailed logging, which quickly facilitates identification of issues.
- Notifications – Concerned parties are notified of events via email, RSS feeds or other means such as smartphone apps, Twitter etc.
- Compliance monitoring –
- The ability to snapshot environments over time and compare them to each other or to snapshots of similar environments and identify differences quickly. Be able to answer the questions ‘What will change during this deployment?’ and ‘What changed during this deployment?’’.
- Demostrable separation of responsibilities, approvals groups and fine grained security.
- Security – LDAP Integration for authentication, authorisation, single sign on. Secure connection protocols to deployment infrastructure. Permission, Role and group based authorisation. Environment segregation. Certificate management.
- Reporting – Customisable dashboards and reports on various aspects of the estates deployment topology, including drill-down metrics
- Visualisation: Views of the deployed topology by environment type, deployed version, component, project or programme or by server, environment or node. Answer questions like ‘Which components at which versions are deployed to the Payments production environment’ or ‘The Statements application is deployed at which versions to which environments?’. Calendar views.
- Simple to install, upgrade, backup and restore the tool.
- Simple to export, import and share configuration between instances of the tool.
- The tool should support full clustering for resiliency and scaleability
- Able to integrate with a broad range of toolchain tools via plugins.
- Able to integrate with a broad range of products via plugins.
- Able to integrate with cloud providers e.g. AWS and Azure.
- Ability to schedule deployments and pipeline execution and impose deployment blackout periods globally, or for specific environment types (e.g. production) or components.
- Extendable by the use of plugins that can be developed by the community.
- Visual, simple, easy to understand and use release orchestrator, editable through the Web UI, which should include:
- Calendar views
- Ability to run parallel and synchronous steps
- Ability to add checkpoints, manual steps, callouts to common tools via Web Services, approvals and quality gates
- Pipelines should include the ability to call other pipelines synchronously and asynchronously
- Take into account change windows, blackout periods
- Handle back out and failure scenarios or pipelines
- Ability to handle deployments to heterogeneous environments
- Visual, simple, easy to understand and use release automator, editable through the Web UI, which should include:
- Large number of out-of-the-box deployment tasks
- Ability to pass inputs/outputs between tasks
- Ability to parameterise tasks with properties that can be set differently between environments or picked up form environment variables
- Properties should be settable at different scopes
- Support for simple conditionals and loops to allow the release automator to be ‘no code/low code’
- Support for environment specific tasks, that only run in the given environments
- ‘Write your own’ deployment task support
- Ability to specify environment differences by abstraction
- Ability to specify required external resources for a component from many sources e.g. SCM tools, Artefact repositories, local and remote filesystems, http/https endpoints etc and allow the user to add plugins for different protocols.
- Ability to pause execution on a target server whilst manual steps are performed, and then restart again, all from within the Web Console
- Ability to pause execution on a target server whilst another job is run on another server. For example stop an application server on one set of servers and then make a call to another server to update a database before resuming the job on the first server.
- This is by no means a comprehensive list, but you’d expect to see these points and more supported in a mature Release Automation and Release Orchestration tool.
For me though, these points fail to convey the most important aspects of such a tool, which are around simplicity, usability and extensibility. Asking the following questions of the tool should help gain an understanding of its suitability:
- Can I quickly install, configure, upgrade and manage the tool without the need for expensive vendor consultants?
- How easy is it to add a multi-component environment to a release pipeline?
- How easy is it to change a component parameter in every target environment and in all pipelines using that component?
- How easy is it to add a deployment task to a component deployment and will this be propagated to all target environments and all pipelines containing this component?
- Can I version a pipeline, as well as the components used by the pipeline?
- Can I quickly and easily redeploy a prior release to a multi-component environment so that it returns to the exact state it was at that prior release?
- Can I employ multiple different back out and failure handling strategies including back out/cleanup at the server, environment and release levels?
- Can I import blueprints and tailor them to my requirements to allow me to get up to speed quickly?
- Can I create new definitions from supplied templates to allow me to get up to speed quickly?
- Can I quickly deploy a component in isolation without the need to run through a pipeline?
- Is it easy to see where I’ve got to in any given pipeline?
Conclusion:
Whilst CI tools and processes are mature and well understood, the continuous delivery space is considerably less so. Vendor tools are often adapted from other primary purposes and may be complex and difficult to configure without expensive vendor consultancy. They may either lack the range of deployment tasks needed to get working quickly out of the box, or the tasks may be ‘black box’ and be inflexible, difficult to decipher or use.